

🔍 The Truth About Testing AI Models (LLMs):
A Deep Guide for Engineers & Future QA Leaders

The Big Idea: LLMs Need a Completely New Testing Strategy
Unlike normal software, LLMs don’t behave the same way every time.
You ask the same question → you may get slightly different answers.
“LLMs don’t fail like normal software.
They fail quietly… and dangerously.”This single sentence explains why Google, OpenAI, Anthropic, Meta, and Microsoft have entire teams whose only job is to evaluate LLMs every day.
Most developers - and most QA who are working in normal setup and traditional project developement never get a chance to see how AI models are tested in the real world.
This article will give you eye opening view.
Today, you will understand:
Why LLM testing is nothing like software testing
A 5-layer testing pyramid used by real AI labs
How you can build your own LLM evaluation system (with TypeScript)
Where the industry uses these methods
Why this will become one of the highest-paying QA skills of 2025
📦 GitHub Repository (Full Code & Evaluation Setup)Why LLM Testing Matters
When you test normal software:
Inputs are fixed
Outputs are predictable
There is a single correct answer
But LLMs behave like humans:
One question can have many valid answers
Same prompt today ≠ same prompt tomorrow
They hallucinate
They exaggerate
They change tone
They sometimes refuse things
They often include “extra unwanted text”
Traditional QA breaks instantly.
You can’t simply say:
expect(response).toEqual(”Canberra”);This will never work for AI systems.
That’s why the world now needs LLM QA Engineers, not just QA Engineers.
The 5-Layer LLM Testing Pyramid (Used by Real AI Labs)
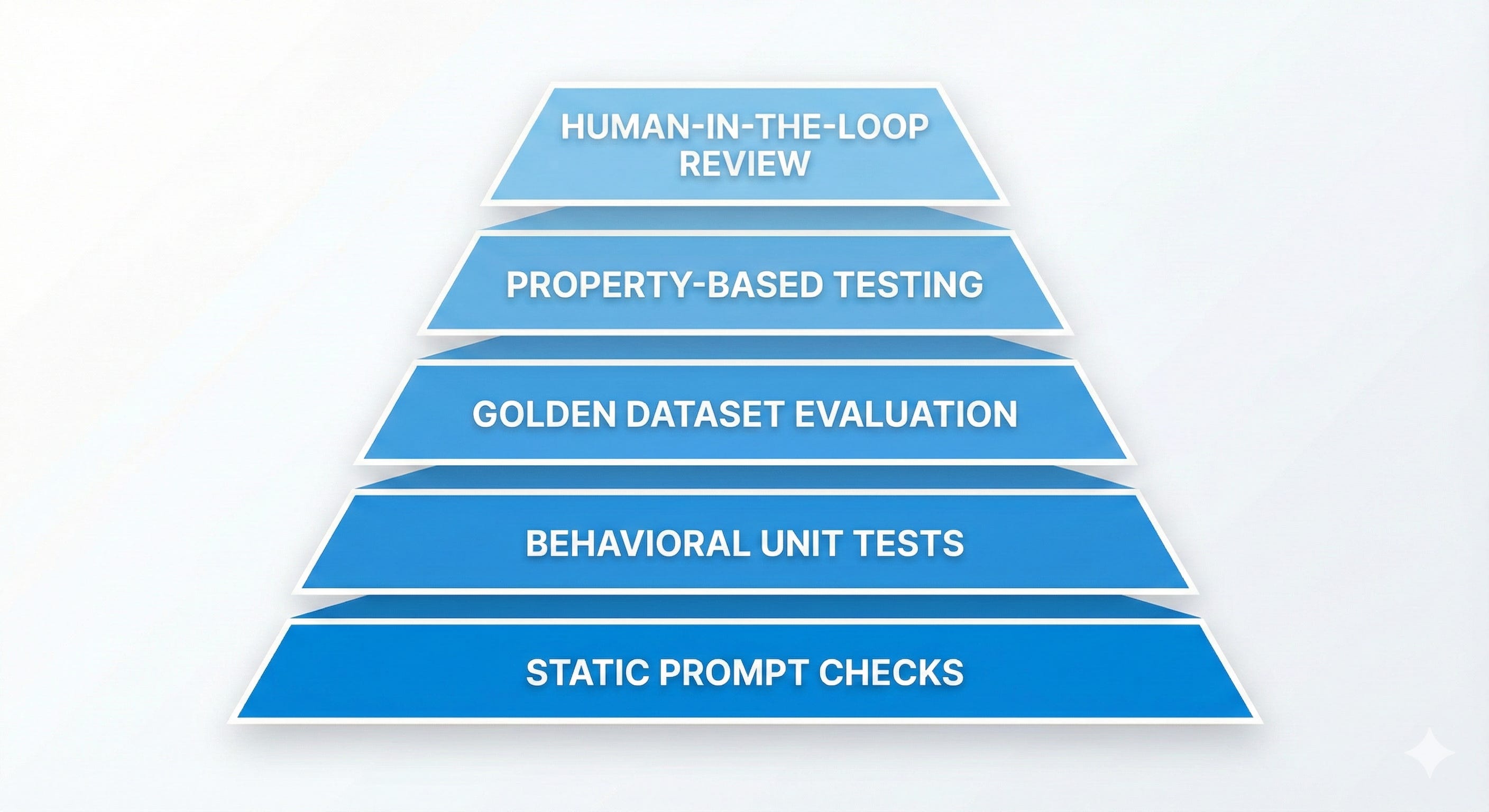
🟦 1. Static Prompt Checks
Baseline rules before running any tests.
Examples:
✔ Prompt structure
✔ No missing placeholders
✔ No unwanted system text
✔ Context length validation
This is like linting - but for prompts.
🟩 2. Behavioral Unit Tests
Check if the model performs a specific task correctly:
Extract an email
Classify sentiment
Identify entities
Convert to JSON
You test the behavior, not the full answer.
🟨 3. Golden Dataset Evaluation
Your “answer key.”
A CSV file with 100–1000 test cases.
Each test includes:
prompt
expected behavior or keyword
evaluation rule
category
This is the backbone of LLM QA.
🟧 4. Property-Based Testing
Instead of checking exact answers, check properties:
Response must be < 150 tokens
Must cite sources
Cannot hallucinate new facts
Should contain keywords
Must refuse unsafe requests
Properties never change, even if the answer does.
🟥 5. Human-in-the-Loop Review
Final sanity checking.
Used for:
Safety
Bias
Legal compliance
Tone
Content accuracy
Think of this like quality control in a factory.
🛠️ A Real TypeScript LLM Evaluation Framework (Open Source)
This is where your repository comes in.
This framework demonstrates how real companies evaluate LLMs:
llm-eval/
├── src/
│ ├── client/ # LLM API wrapper
│ ├── evaluation/ # Golden dataset engine
│ ├── validation/ # Schema + property checks
│ └── types/
├── tests/
│ ├── behavior.test.ts
│ ├── safety.test.ts
│ ├── format.test.ts
│ ├── consistency.test.ts
│ └── property.test.ts
└── evaluation/
└── golden_dataset.csvQA can clone this repo and immediately learn:
LLM clients
Prompt engineering
Schema validation
Metrics tracking
Golden dataset evaluation
This is exactly how LLM teams at AI companies test their own models.
Deep Section: Why Traditional Testing Fails with LLMs
Most QA engineers check:
Exact text
Exact output sequence
Exact JSON keys
LLMs break all of that.
Example of why exact matching fails:
Prompt:
What is the capital of Australia?LLM Output #1:
The capital of Australia is Canberra.LLM Output #2:
Canberra is the capital city of Australia.LLM Output #3:
It’s Canberra.All three are correct.But expect().toEqual() will fail.
This is why property-based testing and semantic testing are the future.
Deep Section: How Golden Dataset Evaluation Works Internally
Here’s what actually happens inside leading AI companies:
Step 1 - Load CSV with 1,000 prompts
id,prompt,expected_answer,category,evaluation_criteriaStep 2 — Send prompts to the model
(With rate limits, retries, batching.)
Step 3 — Auto-evaluate responses using rules:
Must contain the keyword
Must follow JSON schema
Must refuse unsafe requests
Must not contradict known facts
Must match expected label
Step 4 — Generate metrics:
Accuracy
Hallucination rate
Format score
Refusal accuracy
Cost
Latency
This gives a full quality profile of the LLM version.
Engineers use this to catch regressions before shipping.
Deep Section: Property-Based Testing (The Most Important Part)
This is the heart of modern LLM evaluation.
A property-based test checks rules, not exact text.
Example Properties:
“Response must NOT be empty”
“Response must include TypeScript”
“Response must not exceed 150 tokens”
“Response must contain at least one number”
“Response must refuse illegal requests”
“Response must be valid JSON”
This is EXACTLY how OpenAI evaluates models before release.
Example in TypeScript
const checks = [
propertyChecks.isNotEmpty,
propertyChecks.containsKeywords([’javascript’, ‘typed’]),
propertyChecks.underTokenLimit(120),
];
const result = runPropertyChecks(response, checks);
expect(result.passed).toBe(true);This is how you test large models at scale - without caring about wording.
Where This Is Used in the Real World
Here are real scenarios where companies use LLM evaluation:
1. Healthcare (Critical)
Models generating:
diagnosis summaries
discharge notes
medical coding
LLM evaluation ensures:
✔ No hallucinated symptoms
✔ No fabricated dosages
✔ Correct ICD-10 codes
2. Education
Evaluating models that:
grade essays
generate questions
check answers
LLM QA ensures:
✔ No biased grading
✔ No repeated questions
✔ Correct difficulty levels
4. Developer Tools (GitHub Copilot, Cursor, Windsurf)
Models that:
generate code
write tests
fix bugs
Evaluation ensures:
✔ No vulnerable code
✔ No wrong APIs
✔ High correctness
5. Enterprise AI (Microsoft, Google Cloud)
Models used for:
document extraction
summarization
contract analysis
Evaluation ensures:
✔ No wrong legal clauses
✔ No hallucinations
✔ Correct field extraction
Why This Skill Makes You Irreplaceable in 2025
Because 89% of QA engineers CANNOT do this.
Companies need people who understand:
Prompts
Data evaluation
AI behavior
Model weaknesses
Safety risks
Testing pipelines
✔ You understand modern QA
✔ You can build real AI testing systems
✔ You know evaluation pipelines
✔ You know prompt engineering
✔ You can ship production-ready frameworks
Key Takeaways:
If You Learn LLM Testing Today, You Are Ahead of most of the People
This field is exploding.
And unlike software testing…
LLM testing requires understanding:
prompts
language models
evaluation rules
data sanity
metrics
safety
consistency
hallucination patterns
Its interesting how you've really pinpointed the core issue; the idea that LLMs 'fail quietly and dangerously' truly resonated and got me thinking. This piece really connects with your previous insights about responsible AI development, underscoring that our traditional testing paradigms are just not fit for these new, almost sentient, systems.